14 Models for space
We are all familiar with maps - indeed, we often take them for granted. In fact they are a device for encoding a very large amount of information very concisely and efficiently. Spatial data arises when we take measurements which identify spatial position.
Some standard types of problems and data which arise:
- spatial position is the key focus (point patterns);
- values are measured at specified locations (geostatistical data);
- data is available in image form (pixellated);
- values are available for sub-regions (chloropleth data).
Why are spatial data special? Characteristics include:
- standard plotting does not respect the meaning of distance in each co-ordinate;
- it is often helpful to include map and/or topographic information to give spatial context;
- there can be special features of spatial variation .
14.1 Visualising spatial data
There are many powerful tools for plotting spatial data and some of these are mentioned in this section. Many of these are also able to handle some of the special considerations neded for spatial data. The co-ordinate reference system (CRS) is one of those. Latitude and longitude are standard co-ordinates but data can often be spatially indexed in other ways, for example through Easting and Northing in a local reference system. Another issue is the use of shapefiles which contain the boundaries of regions of interest and other information. The sf package provides support for the simple features standard for representing spatial information.
14.1.1 The maps package
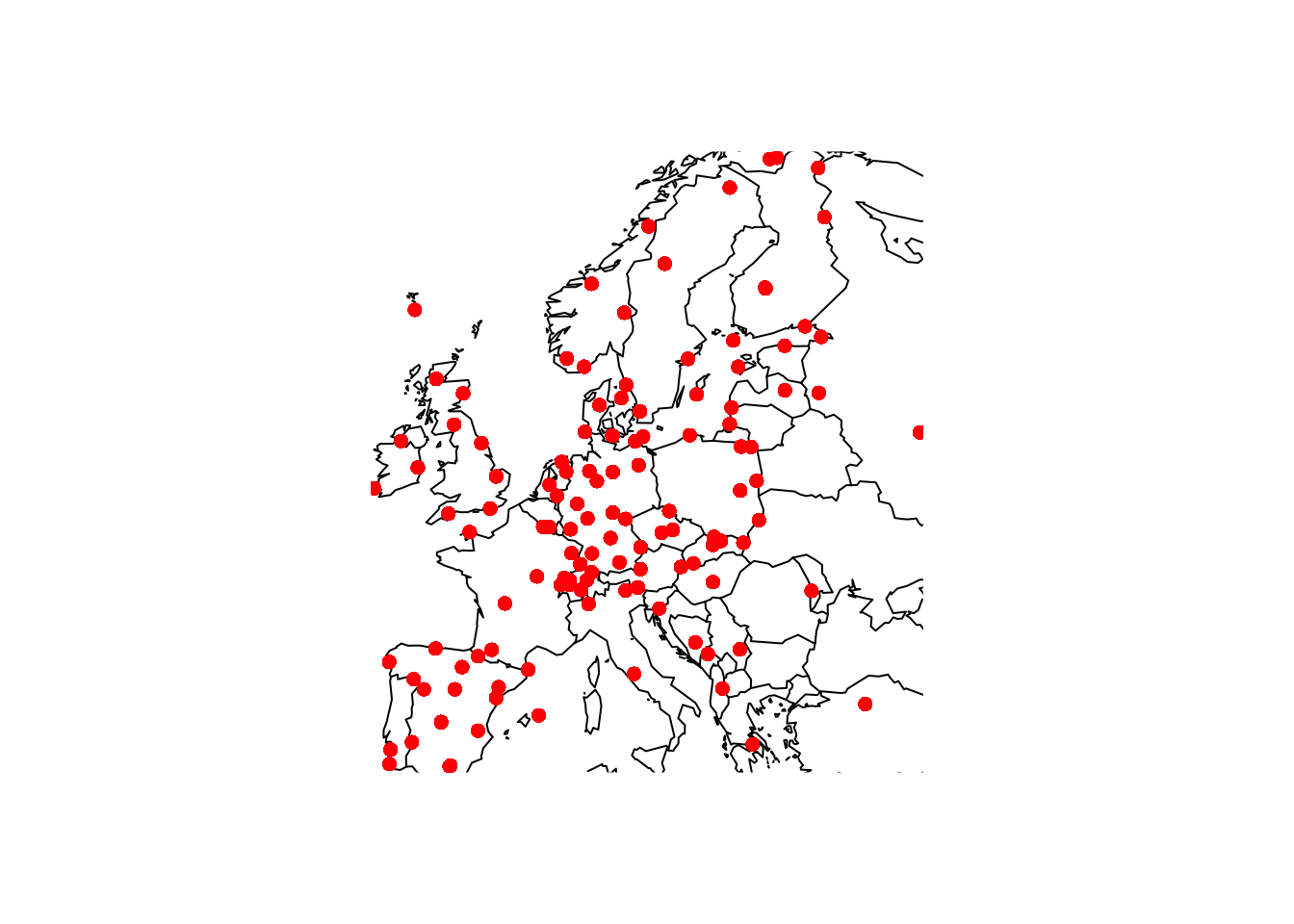
This package provides some basic tools for drawing countries and regions on standard plots. In the chapter on flexible models, data on SO across Europe was used as an example. The code below uses the map function to plot the locations of othe active monitoring stations in January 1990. Notice the use of :: because the function map is present in both the maps package and the tidyverse.
library(rpanel)
library(tidyverse)
library(maps)
SO2_1990 <- SO2 %>% filter(year == 1990 & month == 1)
with(SO2, {
maps::map(xlim = range(longitude), ylim = range(latitude))
points(longitude, latitude, col = "red", pch = 16)
})
14.1.2 leaflet and mapview: interactive maps
One of the very good features of R is that it can connect to many other computing systems, making these environments available without leaving R. One example is the leaflet Javascript library which provides many useful tools for the creation of interactive maps. Here is a simple example. When the code is executed in R it creates a map which can be scrolled and zoomed.
The addTiles function uses Open Street Map by default. Note the use of the ~ symbol in front of variable names. The popup argument allows us to
library(leaflet)
leaflet(SO2_1990) %>% addTiles() %>% addCircles(~longitude, ~latitude,
col = 'red', popup = ~site)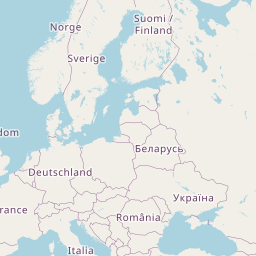

The mapview package offers another means of creating interactive maps and it can use leaflet as its ‘engine’.
14.1.3 ggplot and ggmap
The ggplot2 visualisation system, part of the tidyverse can handle ‘sf’ information through a geom_sf geometry. An example of this is given in the section on areal data below.
14.1.4 tmap
This is a popular package which fits well with the tidyverse format of coding, but it will not be covered here.
14.1.5 spatstat for spatial point patterns
This package has a variety of useful tools for plotting spatial point patterns.
14.1.6 Areal data
There is a often a wish to investigate regional differences in a map, using well defined boundaries to define the regions of interest. This is a good way to visualise the Scottish Referendum data. A shape file, which provides the co-ordinates of the boundary of each region, has been downloaded from the ONS Open Geography Portal. This has been read into ‘R’ as an object, using the ‘sf’ package, and then saved to the file UKLA.Rda. loading this file placess the object councils into the workspace.
The councils object contains details of all the local authorities in the UK so the filter function from the dplyr package is used to select out those identifiers which begin with ‘S’ for Scotland.
library(tidyverse)
library(sf)
path <- rp.datalink("scottish_referendum")
ref <- read.table(path, header = TRUE)
# path <- "~/iCloud/teaching/book/data_more/UKLA.Rda"
# load(path)
path <- "~/iCloud/teaching/book/data_more/Local_Authority_Districts_December_2023_Boundaries_UK_BUC_-1729940581044841319/LAD_DEC_2023_UK_BUC.shp"
# dest <- tempfile()
# download.file(path, dest)
# dest1 <- tempfile()
# unzip(dest, exdir = dest1)
# councils <- read_sf(dest1)
councils <- read_sf(path)
councils <- councils[substr(councils$LAD23CD, 1, 1) == "S", ]We then need to merge these two dataframes, councils and ref. The Council name is the obvious way to link the two but we need to check that the same names have been used. The code below checks whether each name in ref can be found in councils. This throws up some exceptions, so themutatefunction fromdplyris used to recode these names incouncilsto match. Theleft_joinfunction fromdplyrcan then be used to merge therefdataframe intocouncils`.
## [1] "Aberdeen" "Dundee" "Edinburgh" "Eilean Siar" "Glasgow"councils <- mutate(councils,
Scottish.Council = recode(LAD23NM,
`Na h-Eileanan Siar` = "Eilean Siar",
`Aberdeen City` = "Aberdeen",
`Glasgow City` = "Glasgow",
`Dundee City` = "Dundee",
`City of Edinburgh` = "Edinburgh"))
councils <- left_join(councils, ref, by = "Scottish.Council")Now we can plot the council regions as a map, using the geom_sf function in ggplot2 to handle all the drawing for us, and using a variable of interest to define the fill colour. Here we plot the proportion in each region voting ‘no’, plus a rescaling to show which regions have a majority for ‘yes’ or no’, and the level of turnout.
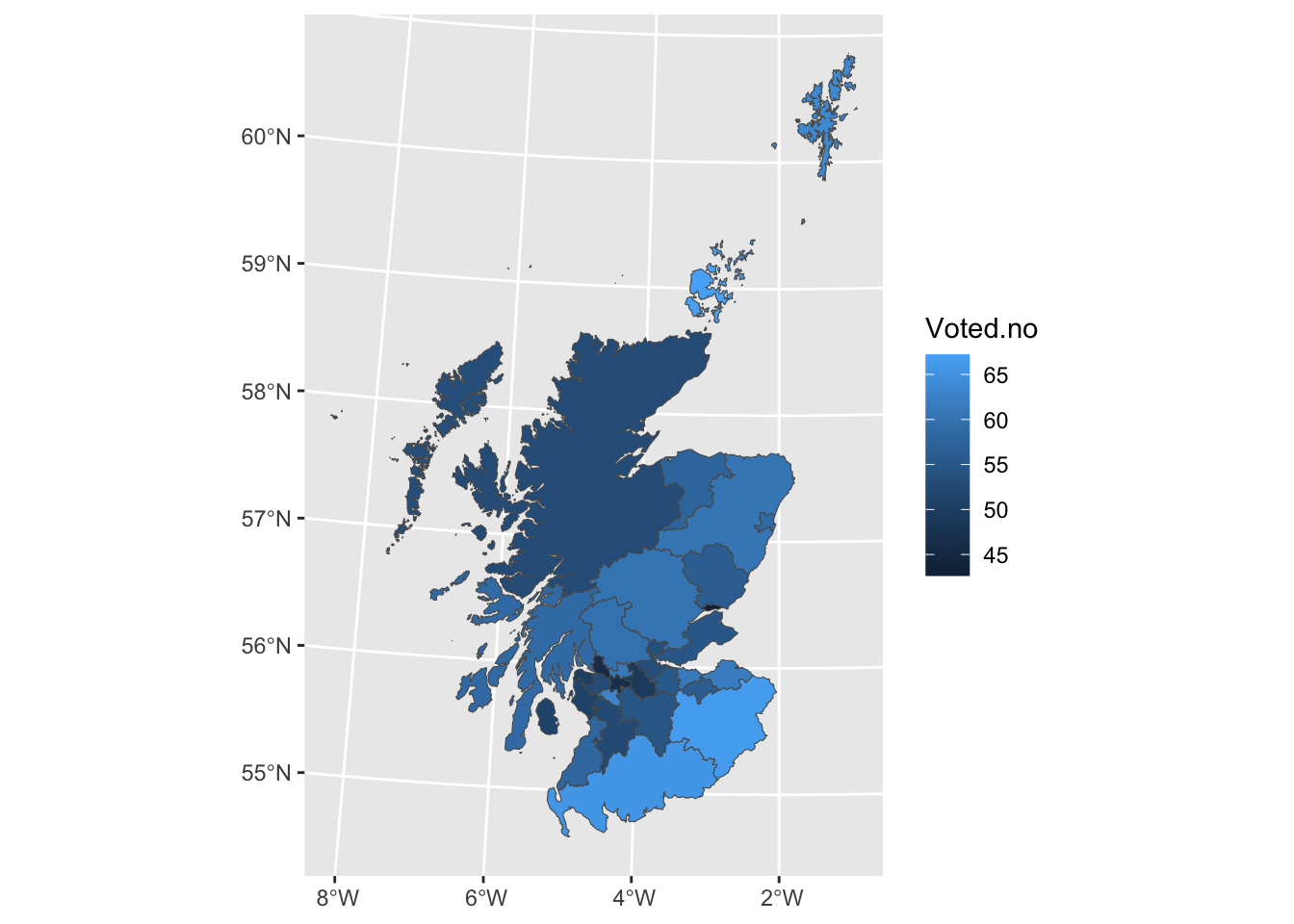
14.1.7 Image data
Not all datasets can be structured easily into simple row and column format. Even for those which can, the dataset may be so large that more efficient and compact forms of storage are required. For example, the netCDF (network Common Data Form) is commonly used to store data which has an array structure, often corresponding to dense spatial and temporal measurements, but involving multiple variables. These datasets may be large in size. Satellite data is one example. The netCDF standard is widely used to achieve efficient storage. The ncdf4 package in R provides tools for reading, handling and plotting this form of data.
An article on a heatwave in the sea around the UK in 2023 used satellite data from the National Oceanic and Atmospheric Administration (NOAA) in the USA. Sea surface temperature is one of the key climate change indicators.
The data for June 18, 2023 can be read from the NOAA repository using the file download mechanism discussed above. The ncdf4 package can then be used to extract the data we need. Use of the functions within the package require careful study of the help files and other documentation. The code below illustrates what can be done.
library(rpanel)
library(ncdf4)
path <- rp.datalink("sea_surface_temperature")
nc_data <- nc_open(path)
# print(nc_data)
lon <- ncvar_get(nc_data, "lon")
lat <- ncvar_get(nc_data, "lat", verbose = FALSE)
anom <- ncvar_get(nc_data, "anom")
fillvalue <- ncatt_get(nc_data, "anom", "_FillValue")
anom[anom == fillvalue$value] <- NA
nc_close(nc_data)This opens the datafile and extracts the latitude and longitude information as vectors which index the rows and columns of the matrix of anomaly (deviations from a long term average) measurements. The print(nc_data) instruction displays a lot of information on the content and source of the dataset but has been commented out above to save space. Missing data are also given the usual R representation.
To plot the data efficiently, the raster package is first used to put the data in raster format.
library(raster)
r <- raster(t(anom), xmn = min(lon), xmx = max(lon), ymn = min(lat), ymx = max(lat), crs = CRS("+proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs+ towgs84=0,0,0"))
r <- flip(r, direction = 'y')
plot(r)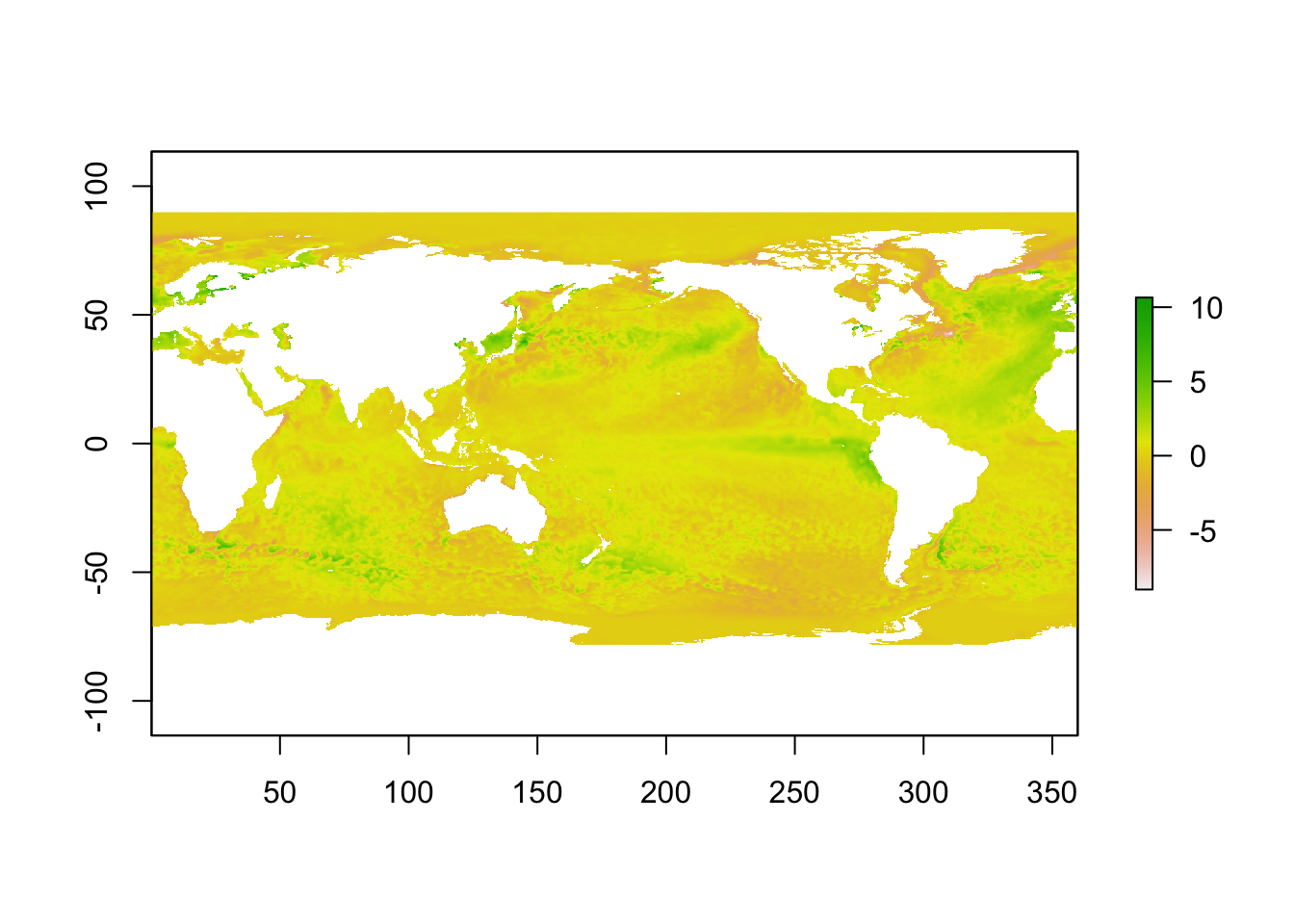
To explore the high temperatures near the UK in more detail, indicators are used to create a smaller array which focusses on the appropriate latitude and longitudes.
ind.lon <- which(lon > 345 & lon < 360)
ind.lat <- which(lat > 48 & lat < 60)
anom_UK <- anom[ind.lon, ind.lat]
r <- raster(t(anom_UK), xmn=min(lon[ind.lon]), xmx=max(lon[ind.lon]),
ymn=min(lat[ind.lat]), ymx=max(lat[ind.lat]),
crs=CRS("+proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs+ towgs84=0,0,0"))
r <- flip(r, direction='y')
plot(r)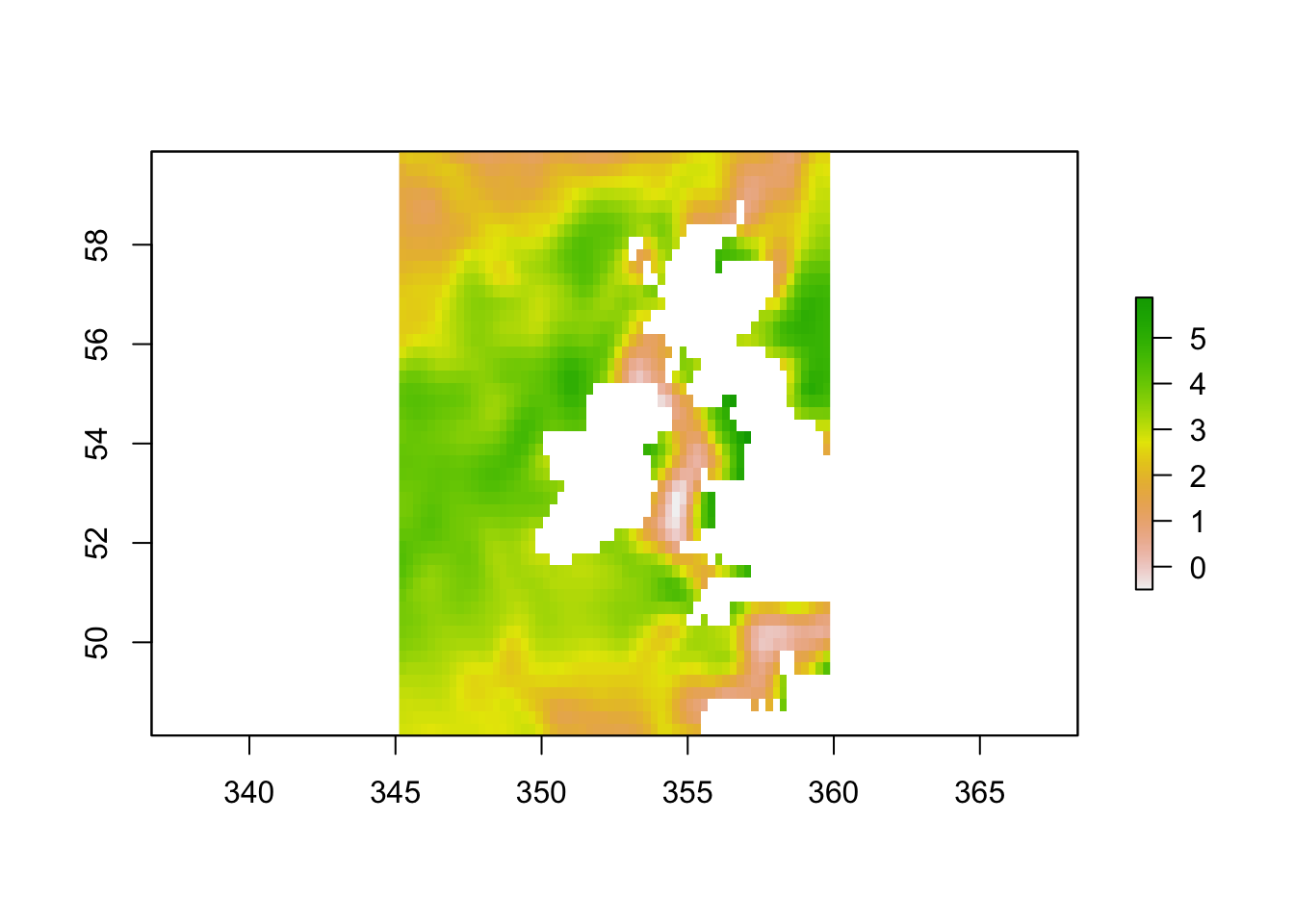
14.1.8 Spatiotemporal animation
The rpanel package includes an rp.plot4d function which uses animation to provide an extra dimension to displays. The rp.spacetime version of this function is intended particularly for data over space and time.
library(rpanel)
Month <- SO2$month + (SO2$year - 1990) * 12
Year <- SO2$year + (SO2$month - 0.5) / 12
location <- cbind(SO2$longitude, SO2$latitude)
mapxy <- maps::map('world', plot = FALSE,
xlim = range(SO2$longitude), ylim = range(SO2$latitude))
back <- function() maps::map(mapxy, add = TRUE)
rp.spacetime(location, Year, SO2$logSO2, col.palette = rev(heat.colors(12)),
background.plot = back)14.2 Models for point pattern data
The lcancer dataframe in the sm package records the spatial positions of cases of laryngeal cancer in the North-West of England between 1974 and 1983, together with the positions of a number of lung cancer patients who were used as controls. The data have been adjusted to preserve anonymity.
data(lcancer, package = 'sm')
ggplot(lcancer, aes(Easting, Northing)) +
geom_point() +
annotate('point', x = 354500, y = 413000, col = 'red', size = 3) +
facet_wrap(~ Cancer)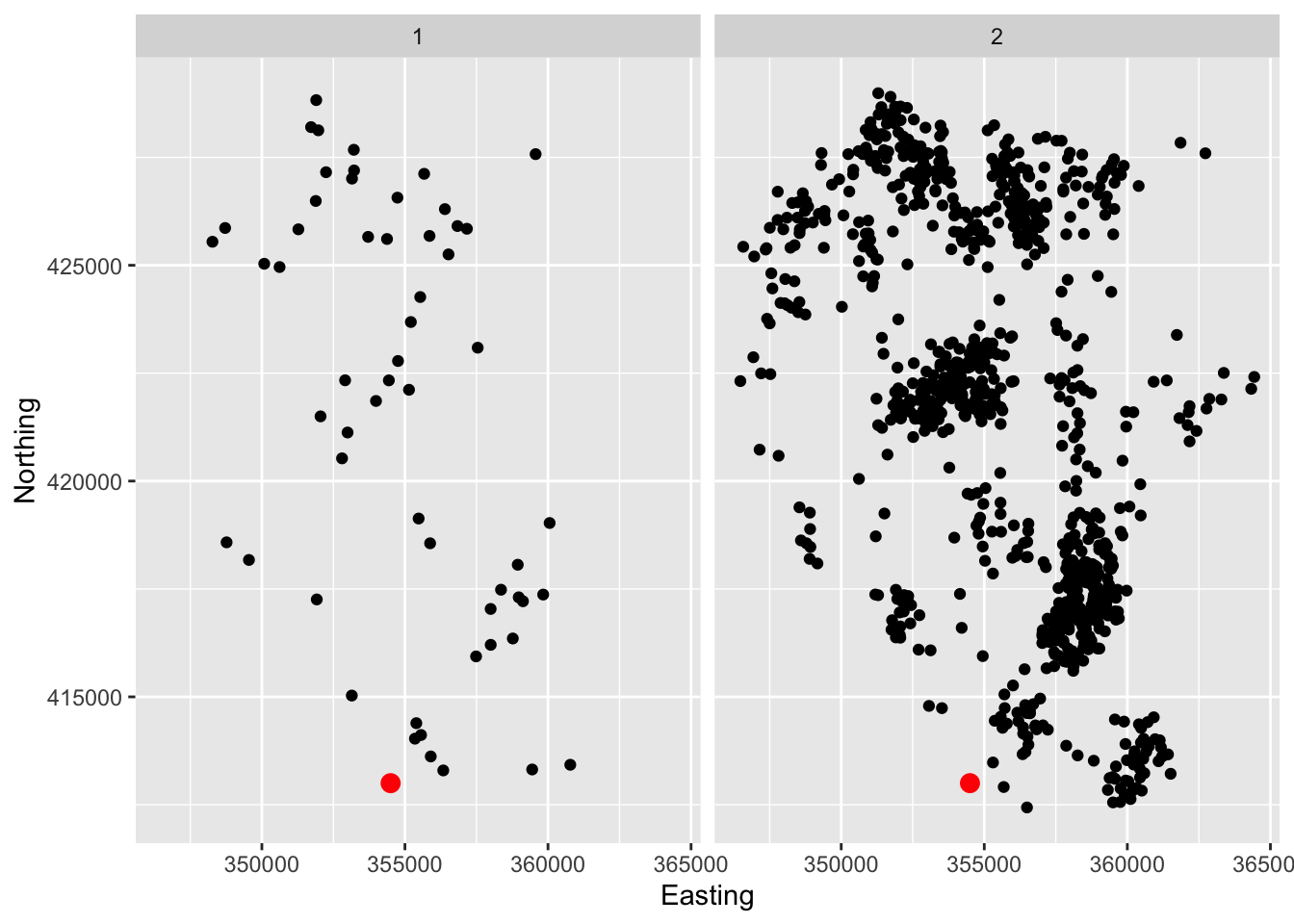
When the information in spatial data is solely the location at which they sit, density estimation can be a useful tool.
ggplot(lcancer, aes(Easting, Northing)) +
geom_density2d_filled() +
annotate('point', x = 354500, y = 413000, col = 'red', size = 3) +
facet_wrap(~ Cancer)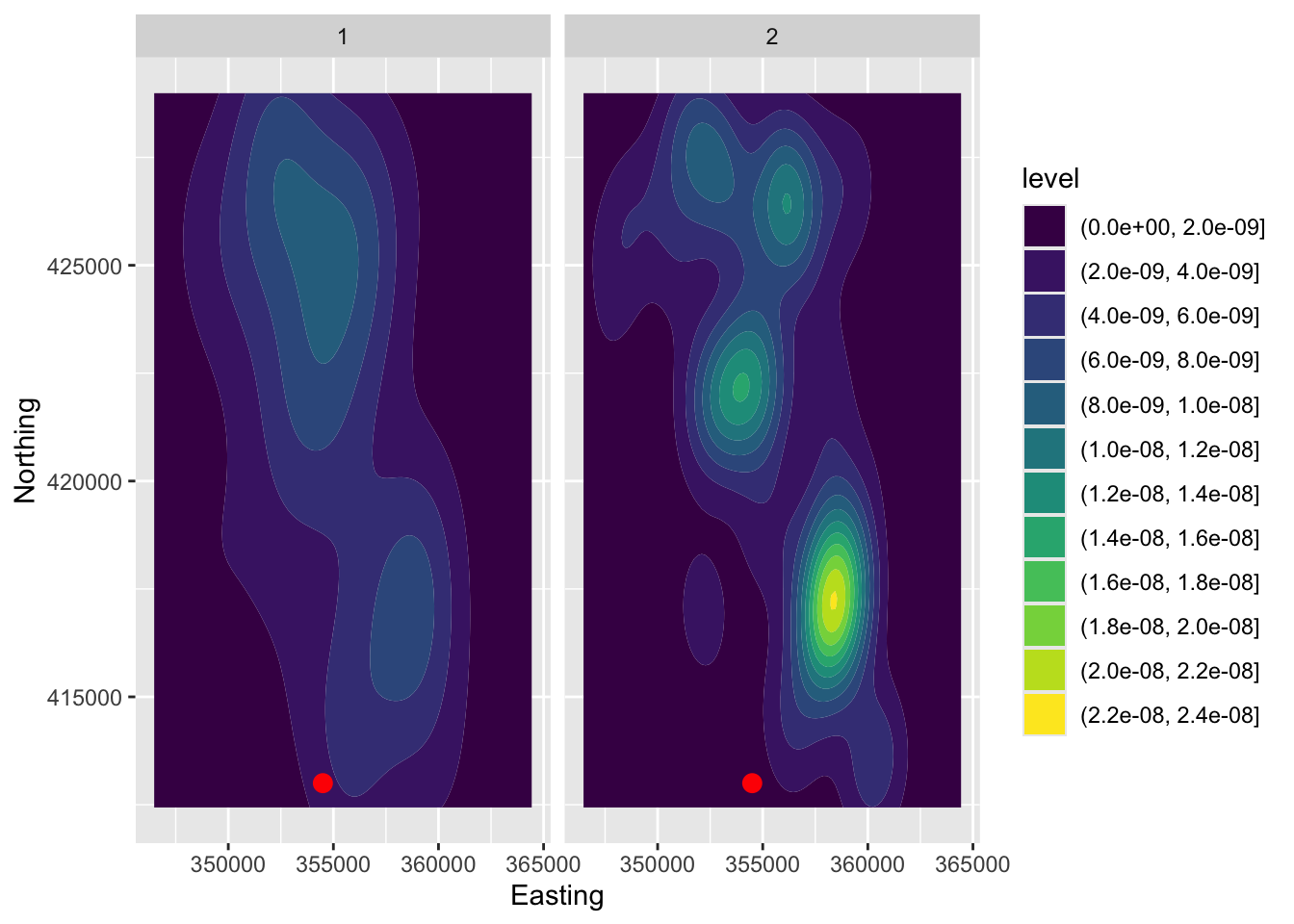
14.3 Geostatistical models
14.3.1 Gaussian processes
Here are three simulations of a Gaussian random field with the same parameters.
library(rpanel)
rp.geosim(panel = FALSE, smgrid = 100)
rp.geosim(panel = FALSE, smgrid = 100)
rp.geosim(panel = FALSE, smgrid = 100)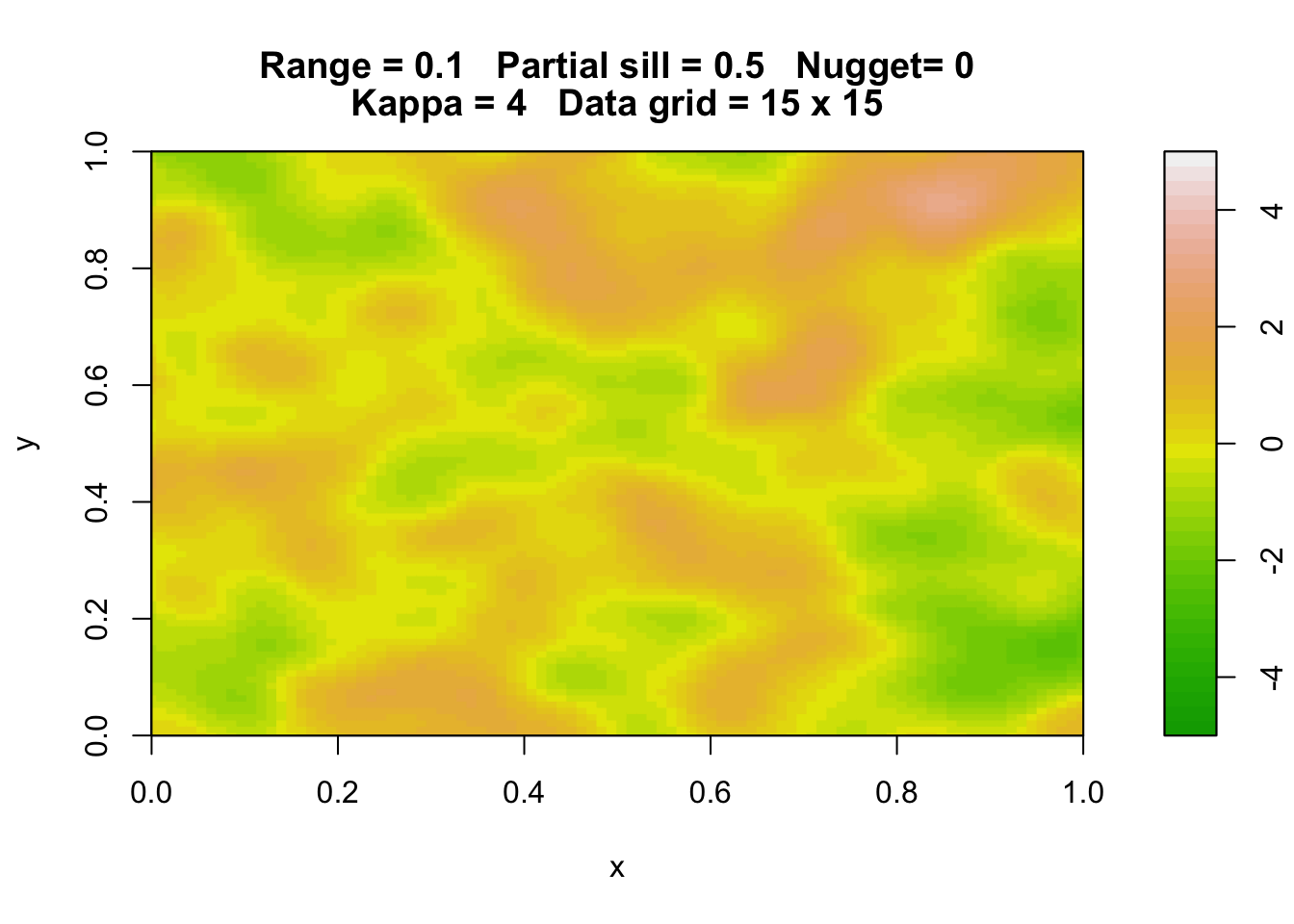
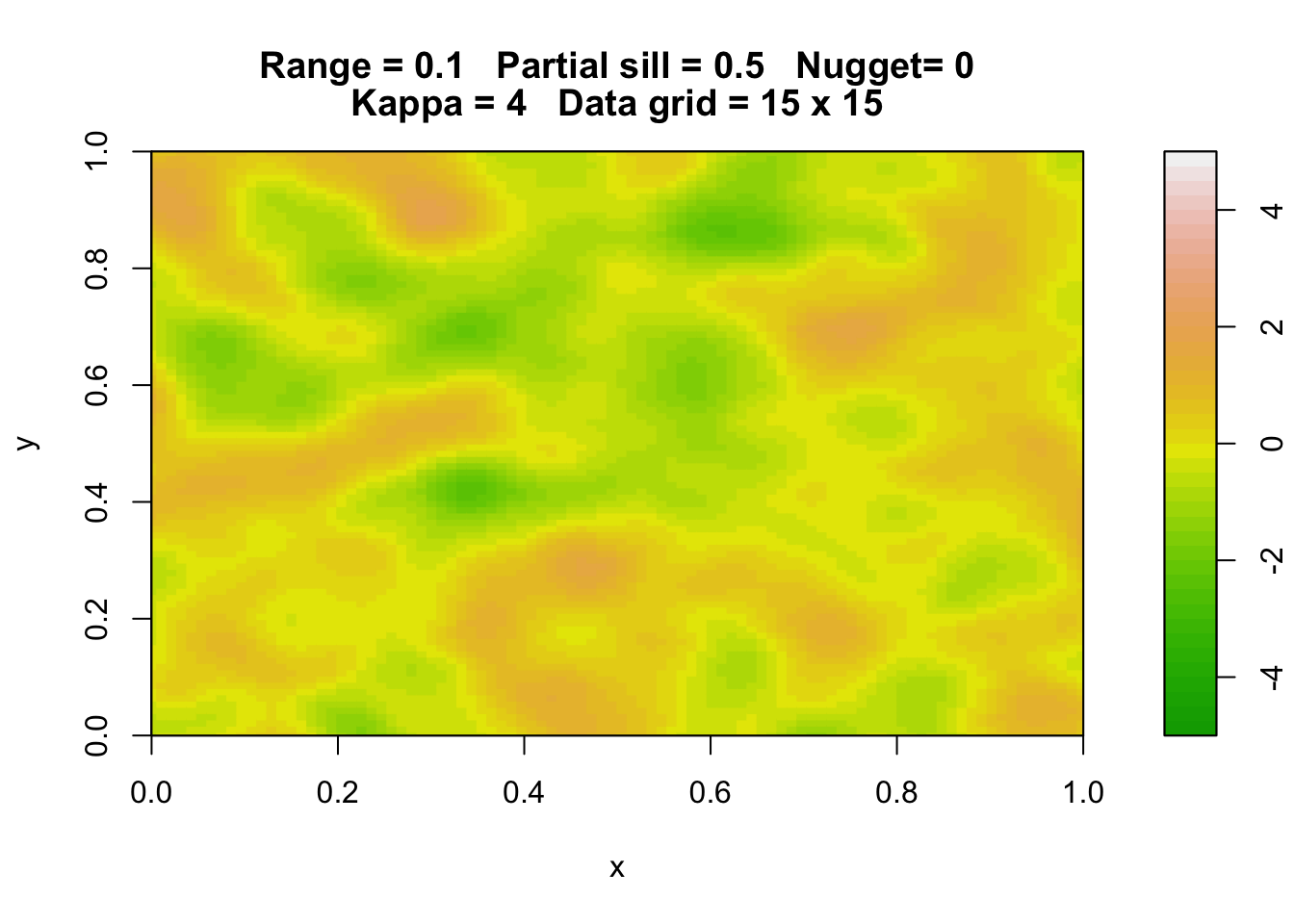
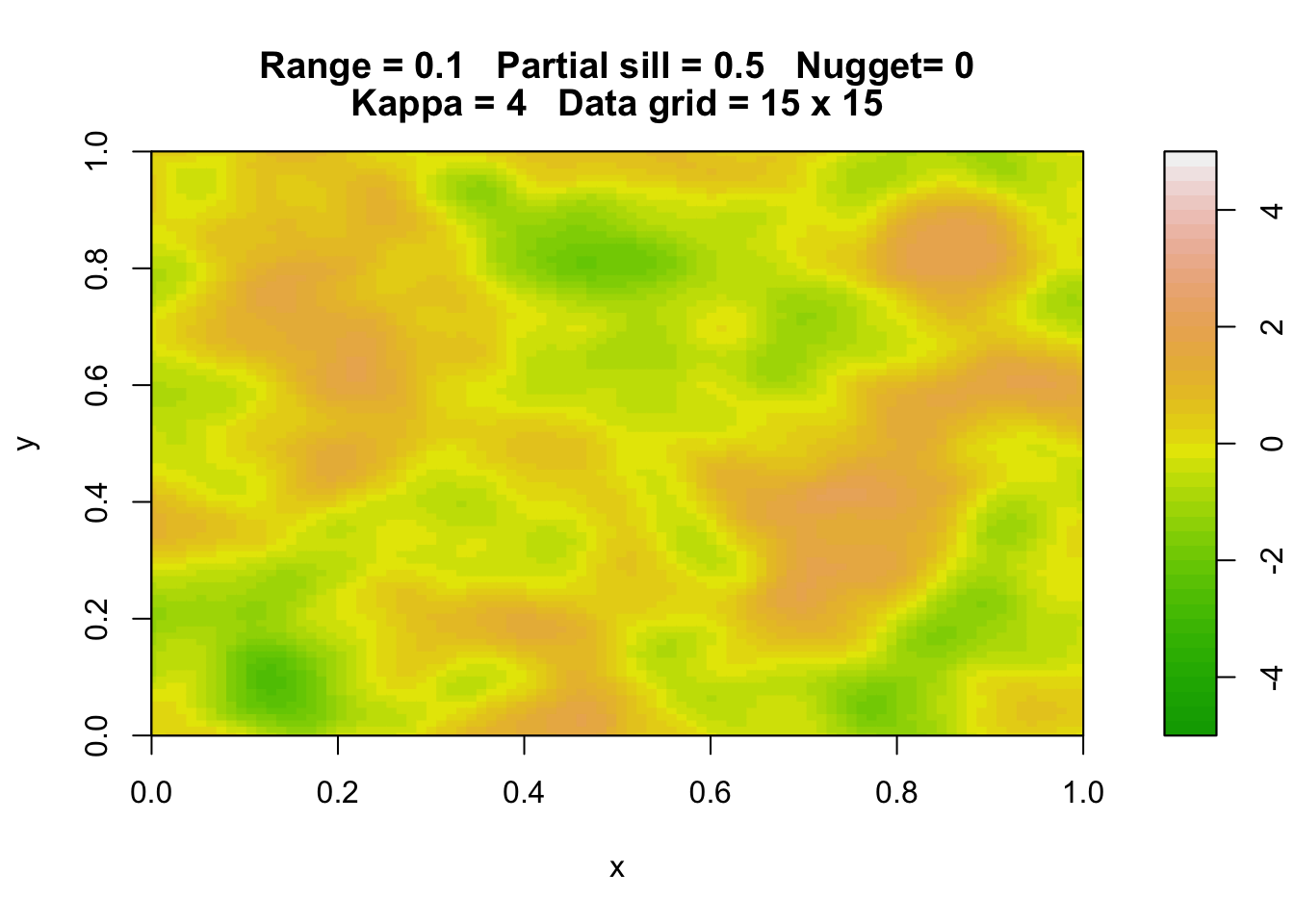
Anisotropy.
14.3.2 Geostatistical models
Fit a non-spatial model and check for spatial correlation.
library(tidyverse)
library(dsm)
data(mackerel, package = 'sm')
km <- latlong2km(mackerel$mack.long, mackerel$mack.lat)
mackerel$mack.long <- km$km.e
mackerel$mack.lat <- km$km.n
mackerel <- mackerel %>%
mutate(long = -mack.long, log.depth = log(mack.depth)) %>%
rename(lat = mack.lat)# test for spatial autocorrelation
model <- lm(log(Density) ~ poly(log.depth, 2) + Temperature, data = mackerel)
library(DHARMa)## This is DHARMa 0.4.6. For overview type '?DHARMa'. For recent changes, type news(package = 'DHARMa')sims <- simulateResiduals(model)
# testSpatialAutocorrelation(sims, mackerel$mack.long, mackerel$mack.lat, plot = FALSE)library(spaMM)
model.spamm <- fitme(log(Density) ~ poly(log.depth, 2) + Temperature + Matern(1 | long + lat),
data = mackerel)
summary(model.spamm)## formula: log(Density) ~ poly(log.depth, 2) + Temperature + Matern(1 |
## long + lat)
## ML: Estimation of corrPars, lambda and phi by ML.
## Estimation of fixed effects by ML.
## Estimation of lambda and phi by 'outer' ML, maximizing logL.
## family: gaussian( link = identity )
## ------------ Fixed effects (beta) ------------
## Estimate Cond. SE t-value
## (Intercept) 2.59146 0.234630 11.045
## poly(log.depth, 2)1 11.89888 1.852050 6.425
## poly(log.depth, 2)2 -9.91492 1.422122 -6.972
## Temperature 0.02202 0.008943 2.462
## --------------- Random effects ---------------
## Family: gaussian( link = identity )
## --- Correlation parameters:
## 1.nu 1.rho
## 1.10634702 0.01976482
## --- Variance parameters ('lambda'):
## lambda = var(u) for u ~ Gaussian;
## long + lat : 0.7714
## # of obs: 279; # of groups: long + lat, 275
## -------------- Residual variance ------------
## phi estimate was 0.561597
## ------------- Likelihood values -------------
## logLik
## logL (p_v(h)): -383.7337## Warning in graphics::rug(resp, side = 2, col = colpts, quiet =
## !is.null(focal_values)): some values will be clipped## Warning in graphics::rug(resp, side = 2, col = colpts, quiet =
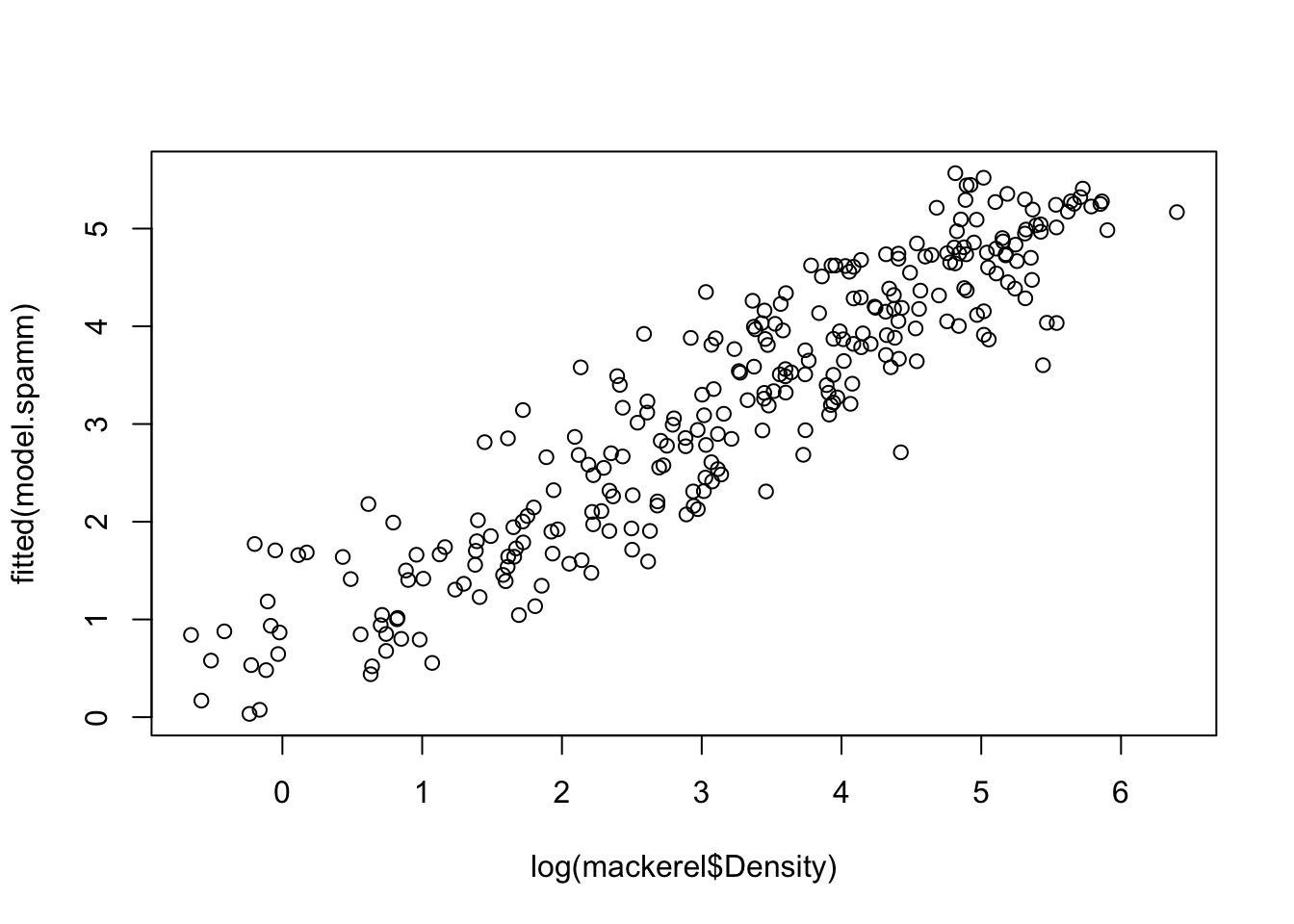
## !is.null(focal_values)): some values will be clippedplot(log(mackerel$Density), fitted(model.spamm))
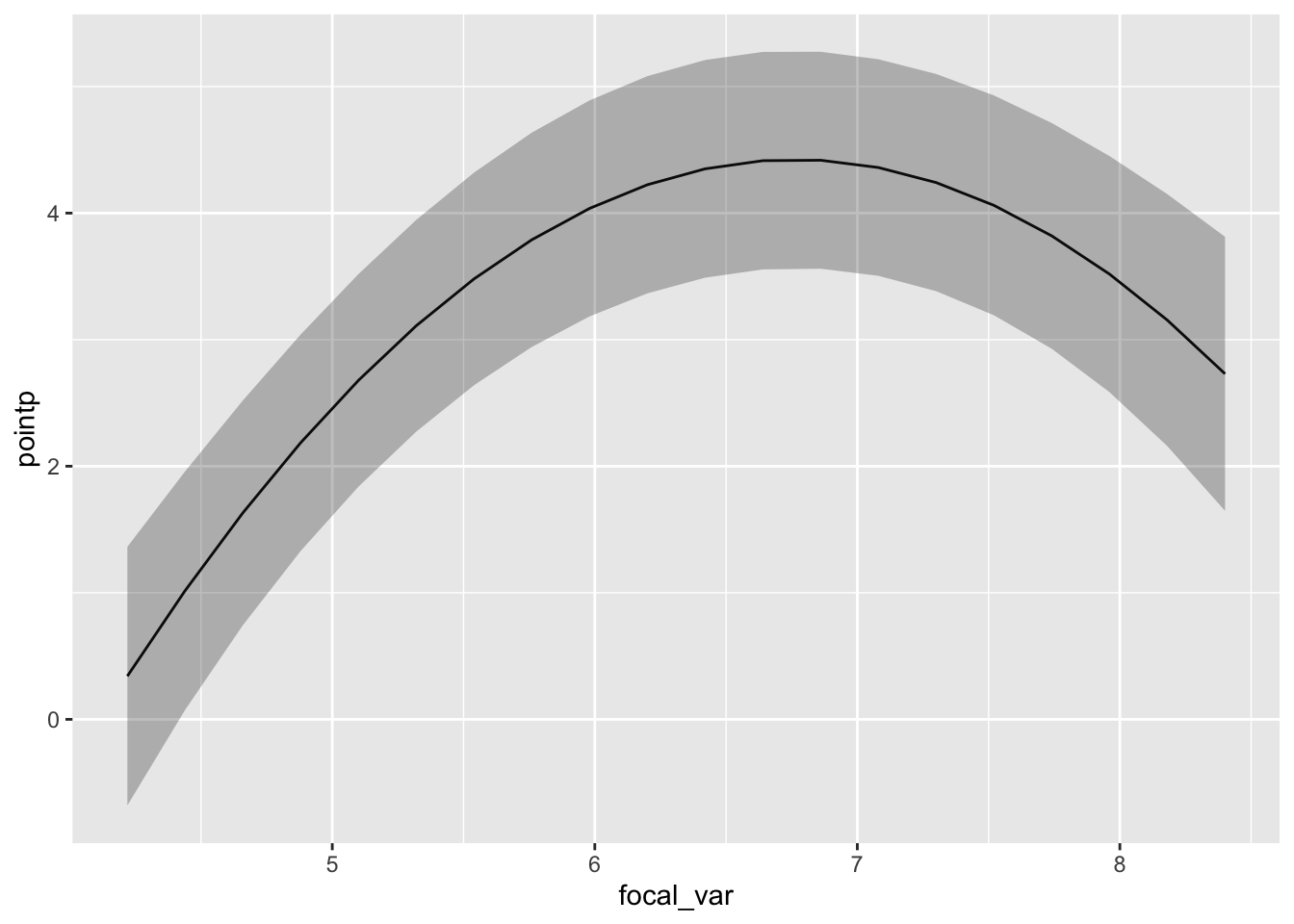
pdep_effects(model.spamm, "log.depth") %>%
ggplot(aes(focal_var, pointp)) + geom_line() +
geom_ribbon(aes(ymin = low, ymax = up), alpha = 0.3)
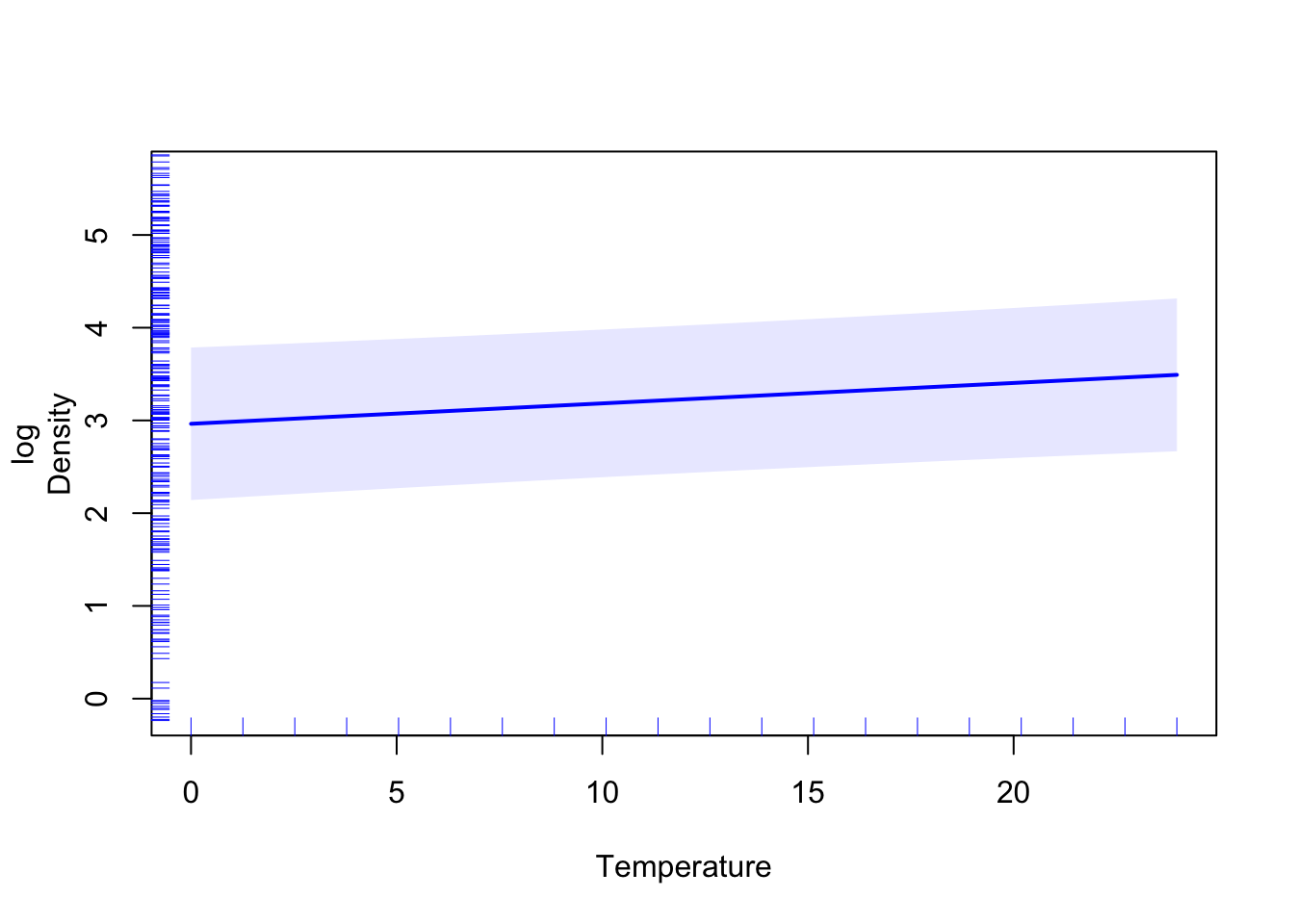
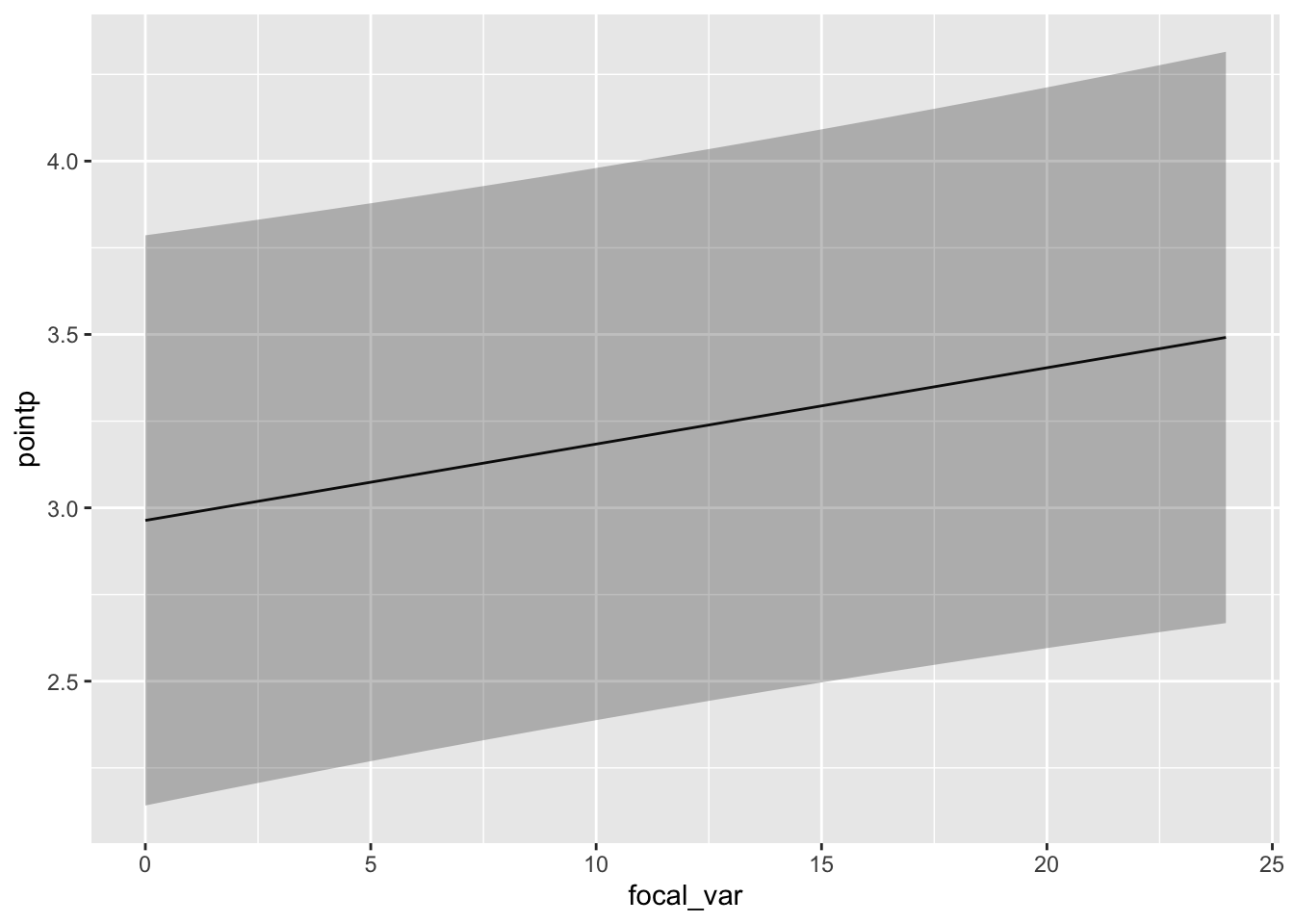
pdep_effects(model.spamm, "Temperature") %>%
ggplot(aes(focal_var, pointp)) + geom_line() +
geom_ribbon(aes(ymin = low, ymax = up), alpha = 0.3)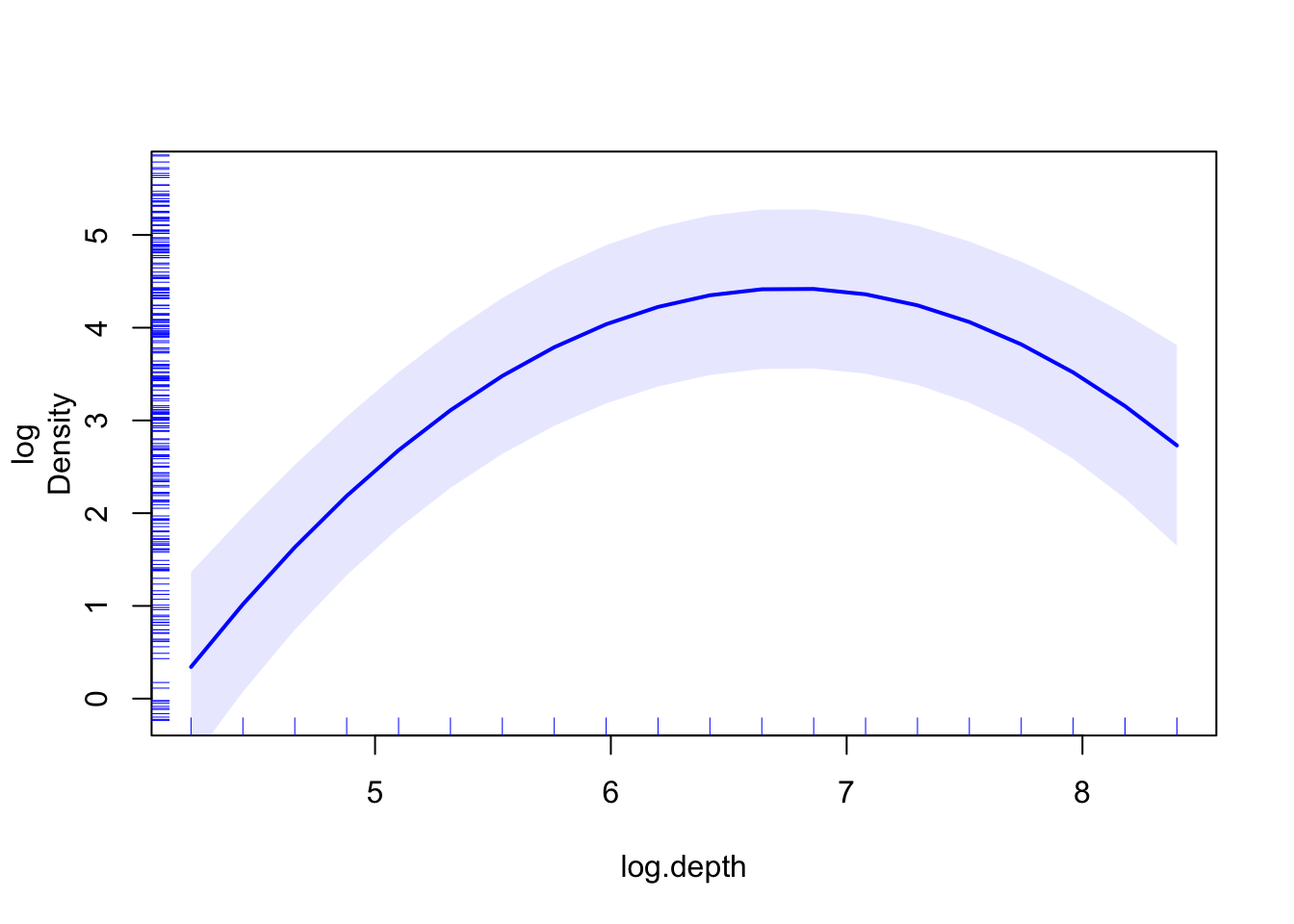
newdat.space <- expand.grid(log.depth = mean(mackerel$log.depth),
Temperature = mean(mackerel$Temperature),
long = seq(min(mackerel$long), max(mackerel$long), length = 50),
lat = seq(min(mackerel$lat), max(mackerel$lat), length = 50))
library(spatstat)
dst <- crossdist(newdat.space$long, newdat.space$lat, mackerel$long, mackerel$lat)
dst <- apply(dst, 1, min)
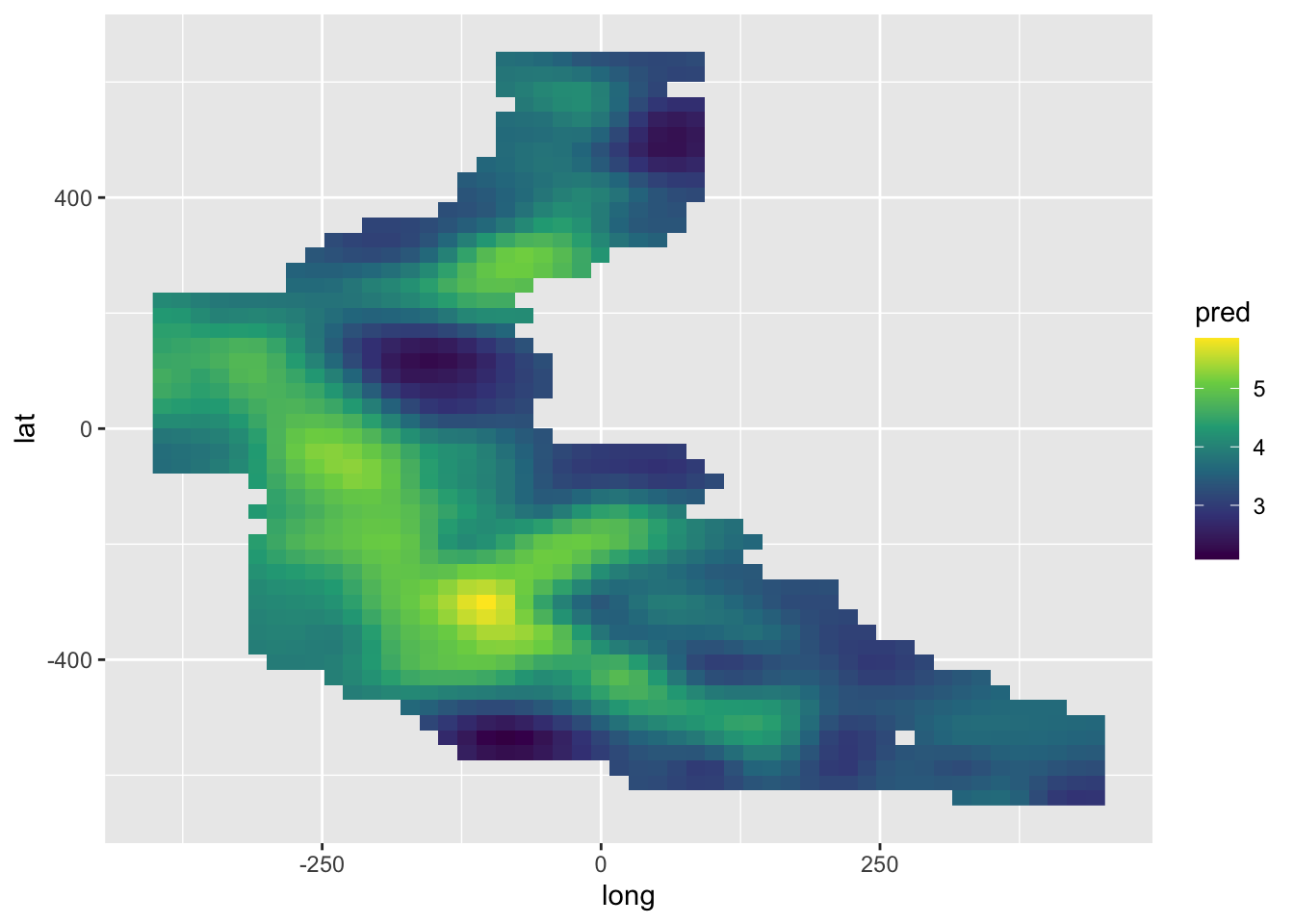
newdat.space <- newdat.space[dst < 50, ]pred <- c(predict(model.spamm, newdat.space))
ggplot() +
geom_raster(aes(long, lat, fill = pred), data = newdat.space) +
scale_fill_viridis_c() +
geom_point(aes(long, lat), data = mackerel)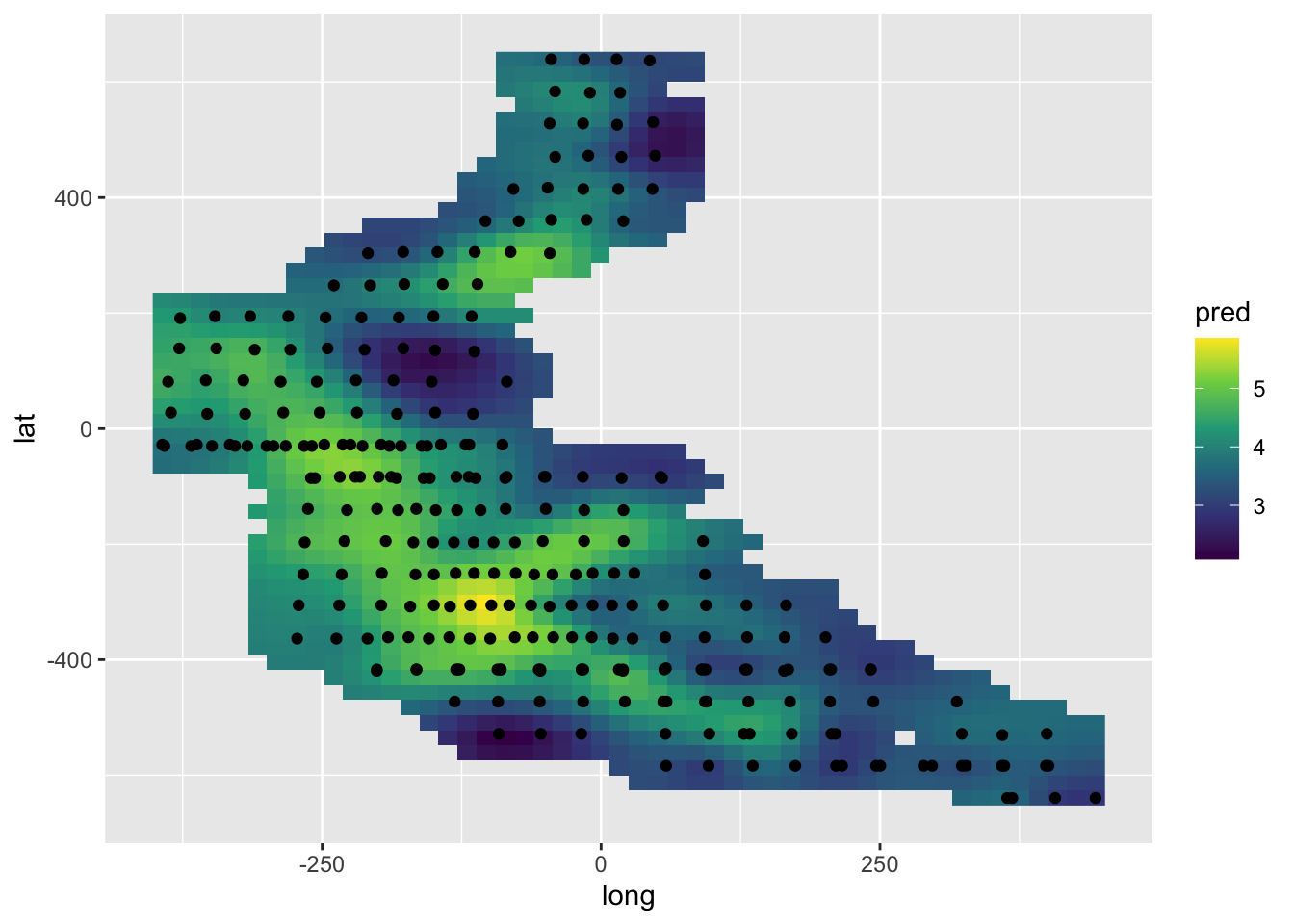
library(mgcv)
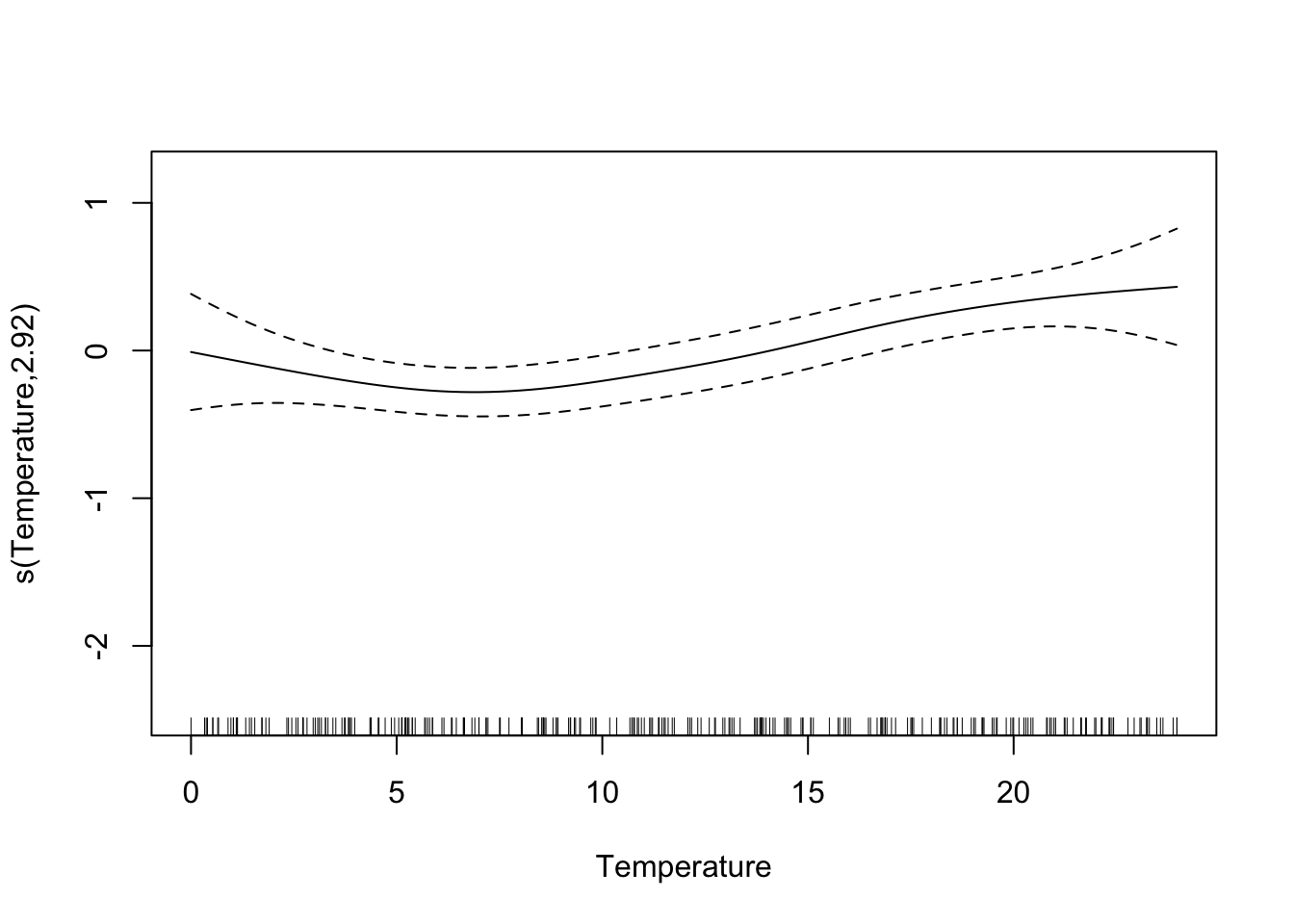
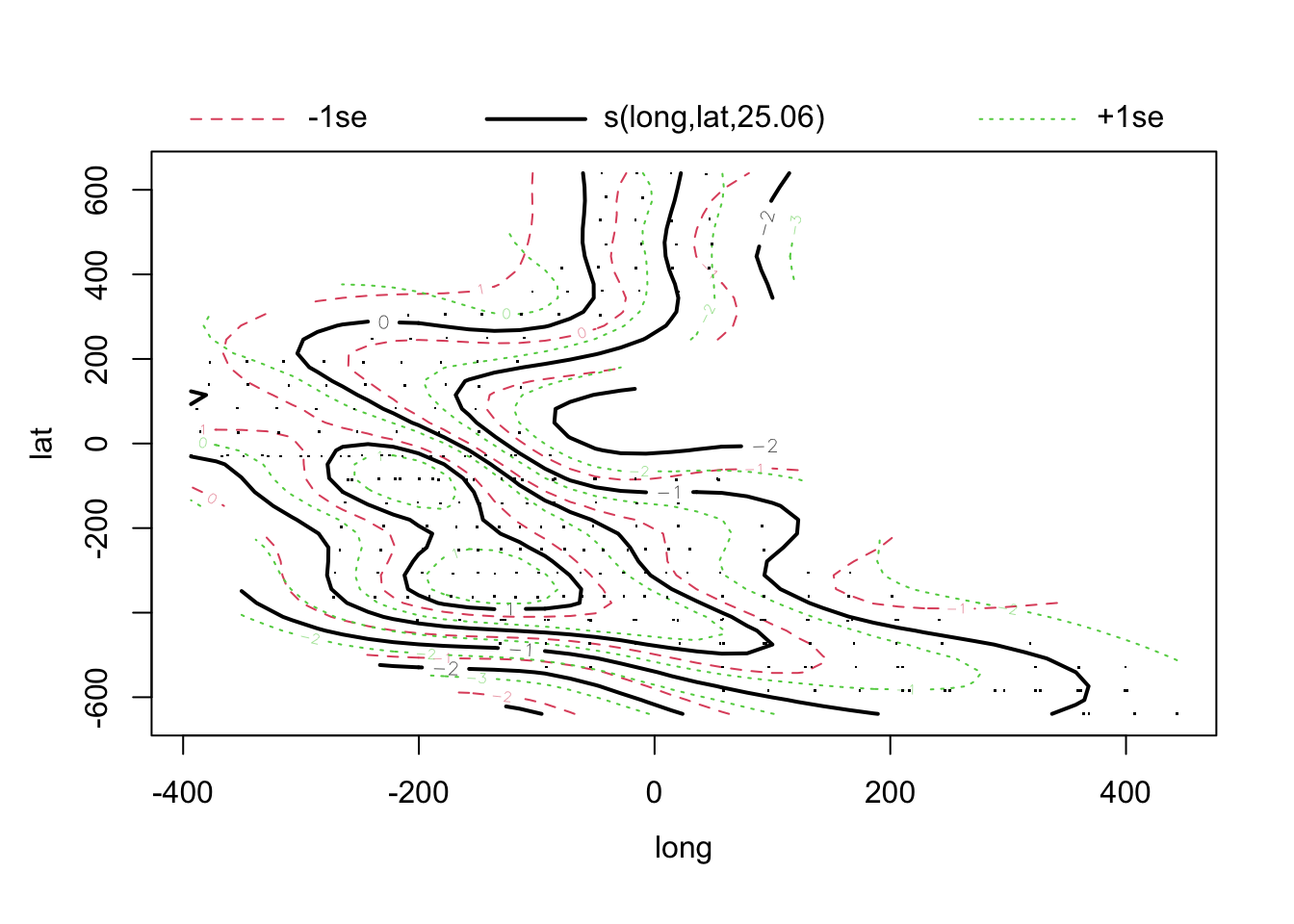
model.gam <- gam(log(Density) ~ s(log.depth) + s(Temperature) + s(long, lat), data = mackerel)
summary(model.gam)##
## Family: gaussian
## Link function: identity
##
## Formula:
## log(Density) ~ s(log.depth) + s(Temperature) + s(long, lat)
##
## Parametric coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.22409 0.05364 60.11 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Approximate significance of smooth terms:
## edf Ref.df F p-value
## s(log.depth) 2.597 3.298 12.101 2.98e-07 ***
## s(Temperature) 2.922 3.663 4.720 0.00172 **
## s(long,lat) 25.057 27.996 6.043 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## R-sq.(adj) = 0.698 Deviance explained = 73.1%
## GCV = 0.90515 Scale est. = 0.8027 n = 279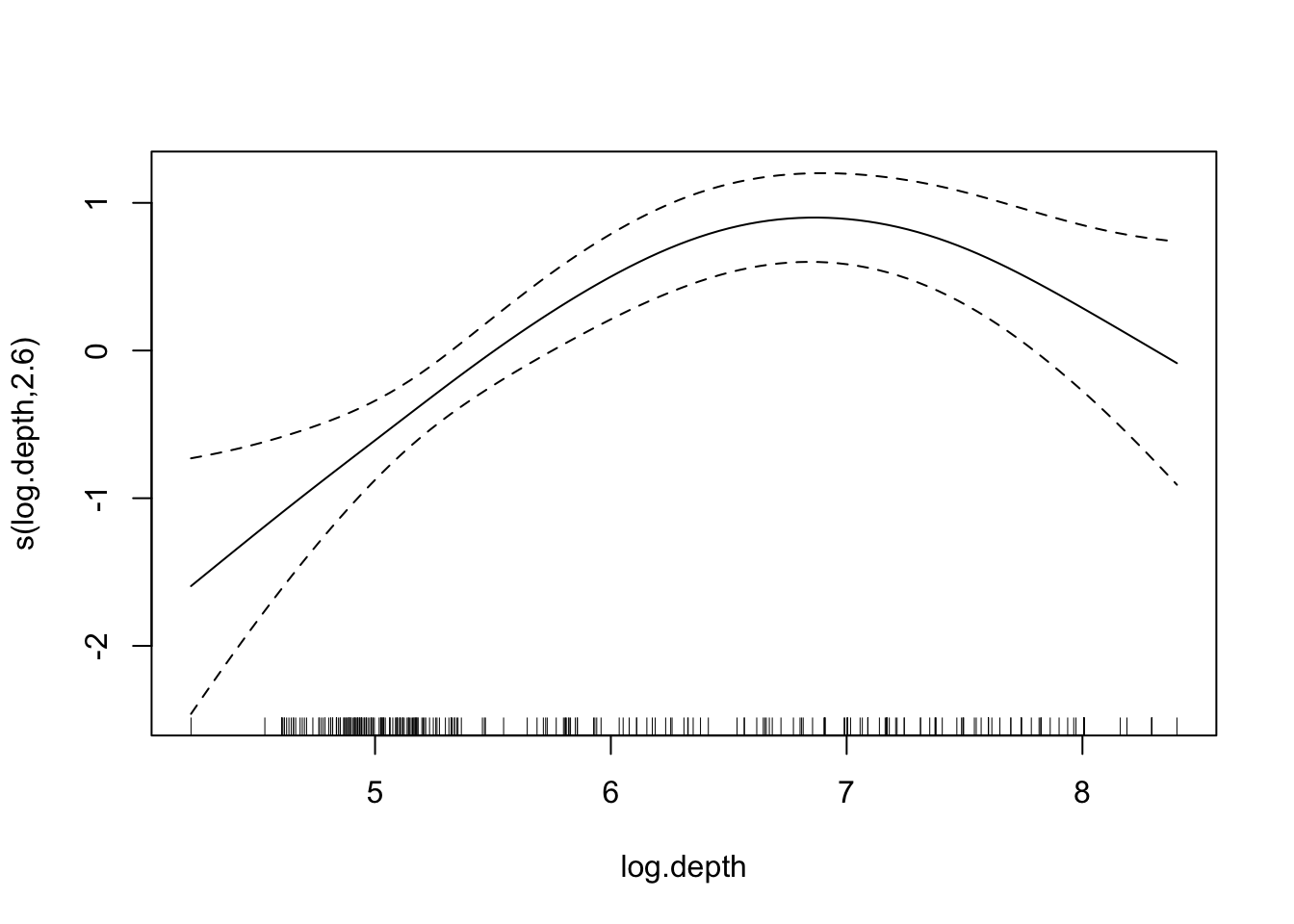
pred <- c(predict(model.gam, newdat.space))
ggplot() +
geom_raster(aes(long, lat, fill = pred), data = newdat.space) +
scale_fill_viridis_c()
# geom_point(aes(long, lat), data = mackerel)
pred <- c(predict(model.spamm, newdat.space))
ggplot() +
geom_raster(aes(long, lat, fill = pred), data = newdat.space) +
scale_fill_viridis_c()
# geom_point(aes(long, lat), data = mackerel)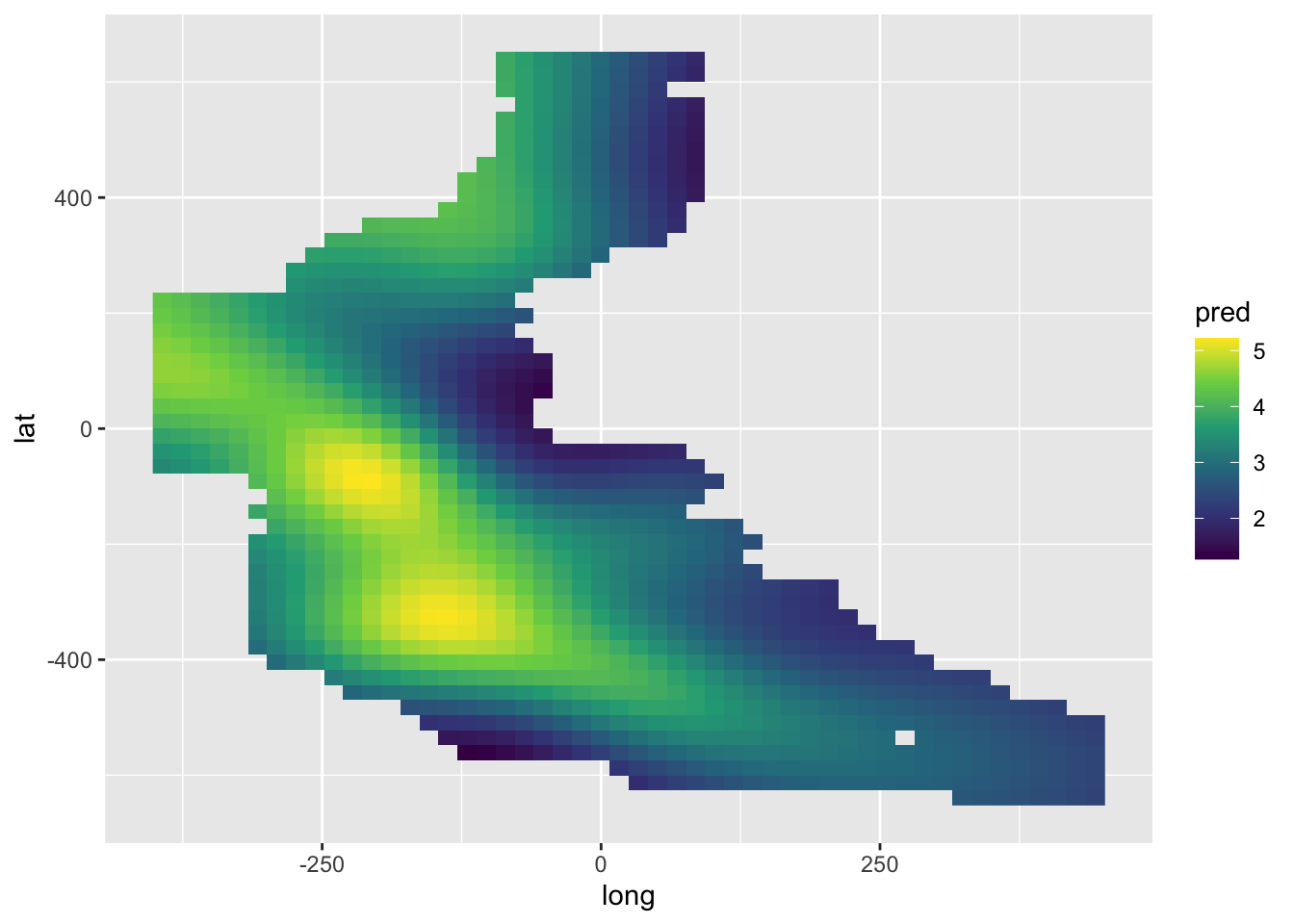
There are an increasing number of options, including:
geoRwhen the focus is primarily on the spatial effects, without additional covariates;inlafor a Bayesian modelling approach;mgcvfor an additive modelling approach.prevmap
glmmTMB See spatial example at https://cran.r-project.org/web/packages/glmmTMB/vignettes/covstruct.html and https://rpubs.com/Rebekko/922320
nlme is also an option: https://stats.oarc.ucla.edu/r/faq/how-do-i-model-a-spatially-autocorrelated-outcome/
Gómez-Rubio (2020), with on-line version at https://becarioprecario.bitbucket.io/inla-gitbook/ McElreath (2018) Krainski et al. (2018), with on-line version at https://becarioprecario.bitbucket.io/spde-gitbook/index.html
14.4 Models for areal data
An example of areal data was given in the visualisation section above. This referred to the voting patterns in the 2014 Scottish Referendum. Visual displays are very informative but when the question of interest concerns the influence of potential covariates a model is then needed to give insight into what is happening.
The CARBayes package (Lee, 2013) provides numerous powerful tools to help. The example in this section constructs a model of house prices in Glasgow. The code used follows closely the example provided in the CARBayes package vignette. The text in this section gives only a sketch of the analysis.
The tools required to organise, plot and model the data are spread across several packages. R is a very collaborative environment!
library(CARBayes)
library(CARBayesdata)
library(sf)
library(tidyverse)
library(GGally)
library(mapview)
library(RColorBrewer)
library(spdep)
library(coda)The variables available for the model are shown below.
## IZ price crime rooms sales driveshop type logprice
## 1 S02000260 112.250 390 3 68 1.2 flat 4.720729
## 2 S02000261 156.875 116 5 26 2.0 semi 5.055449
## 3 S02000262 178.111 196 5 34 1.7 semi 5.182407
## 4 S02000263 249.725 146 5 80 1.5 detached 5.520360
## 5 S02000264 174.500 288 4 60 0.8 semi 5.161925
## 6 S02000265 163.521 342 4 24 2.5 semi 5.096941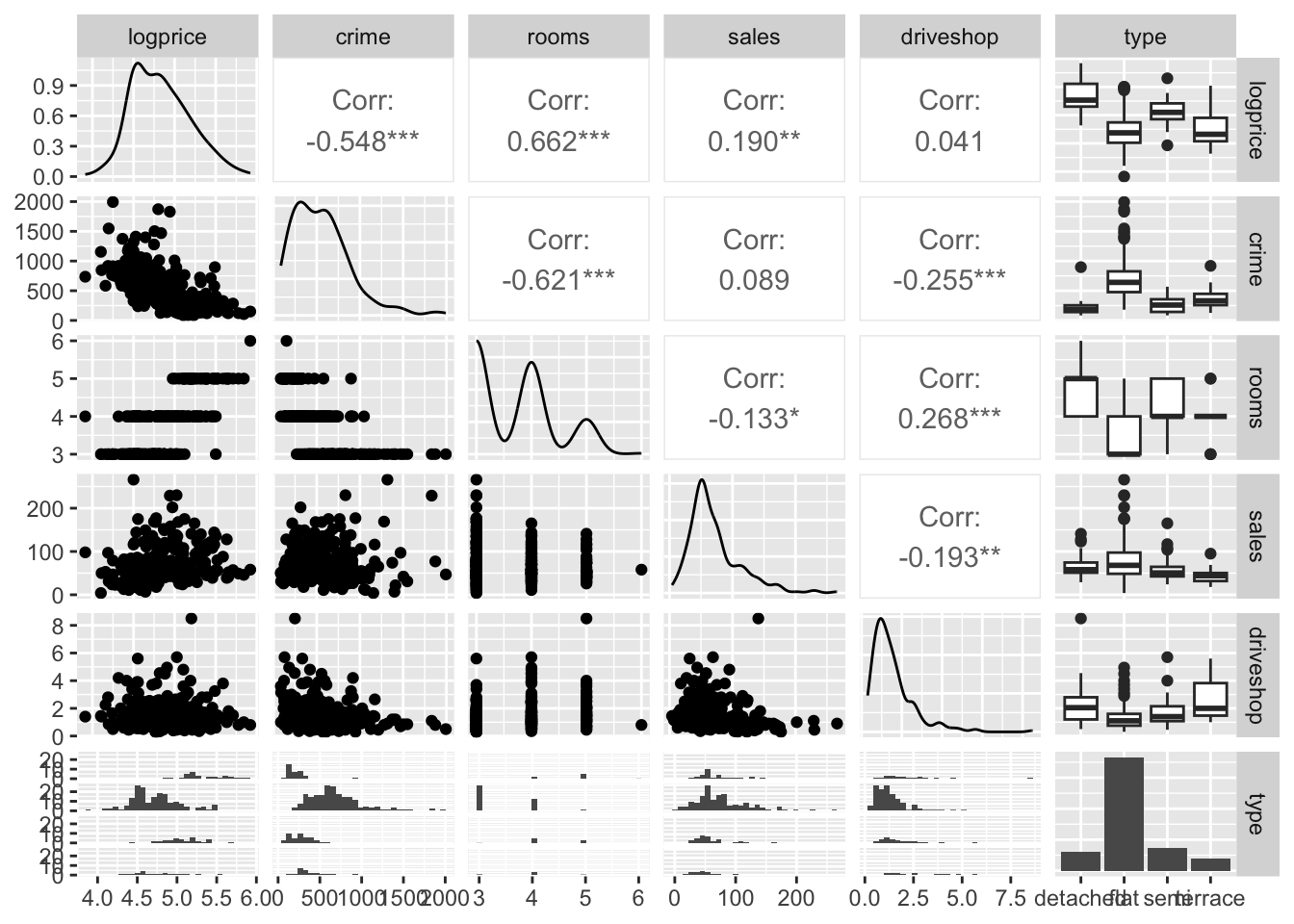
We need to collate this with the spatial information for the region, ensuring that the co-ordinate system is moved to longitude and latitude.
data(GGHB.IZ)
pricedata.sf <- merge(GGHB.IZ, pricedata, by = "IZ", all.x = FALSE)
pricedata.sf <- st_transform(x=pricedata.sf,
crs='+proj=longlat +datum=WGS84 +no_defs')We can now plot price information on a map using mapview.
map1 <- mapview(pricedata.sf, zcol = "price",
col.regions = brewer.pal(9, "YlOrRd"),
alpha.regions = 0.6, layer.name = "Price",
lwd = 0.5, col = "grey90", homebutton = FALSE)
removeMapJunk(map1, junk = c("zoomControl", "layersControl"))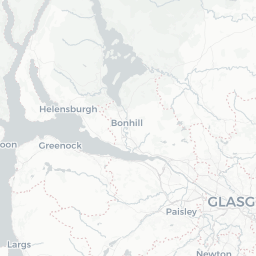
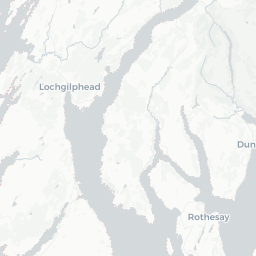
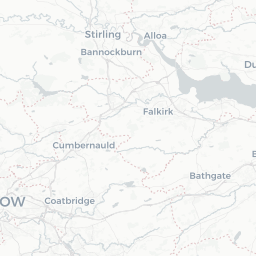
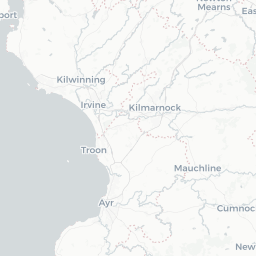
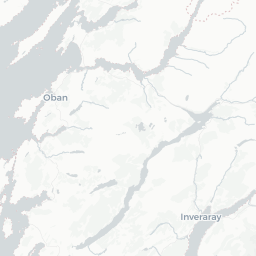
When the residuals from a standard (non-spatial) linear model are examined, there is clear evidence of spatial correlation. In preparation for a spatial model, the neighbourhood structure of the different areas is set up.
This allows us to fit a model which includes all the covariates of interest but also incorporates spatial correlation. We can check that the MCMC has stabilised.
## form <- logprice~crime+rooms+sales+factor(type) + driveshop
## chain <- S.CARleroux(form, data = pricedata.sf, family = "gaussian",
## W = W, burnin = 100000, n.sample = 300000, thin = 100,
## n.chains = 3, n.cores = 3)
plot(chain$sample$beta[ ,2:4])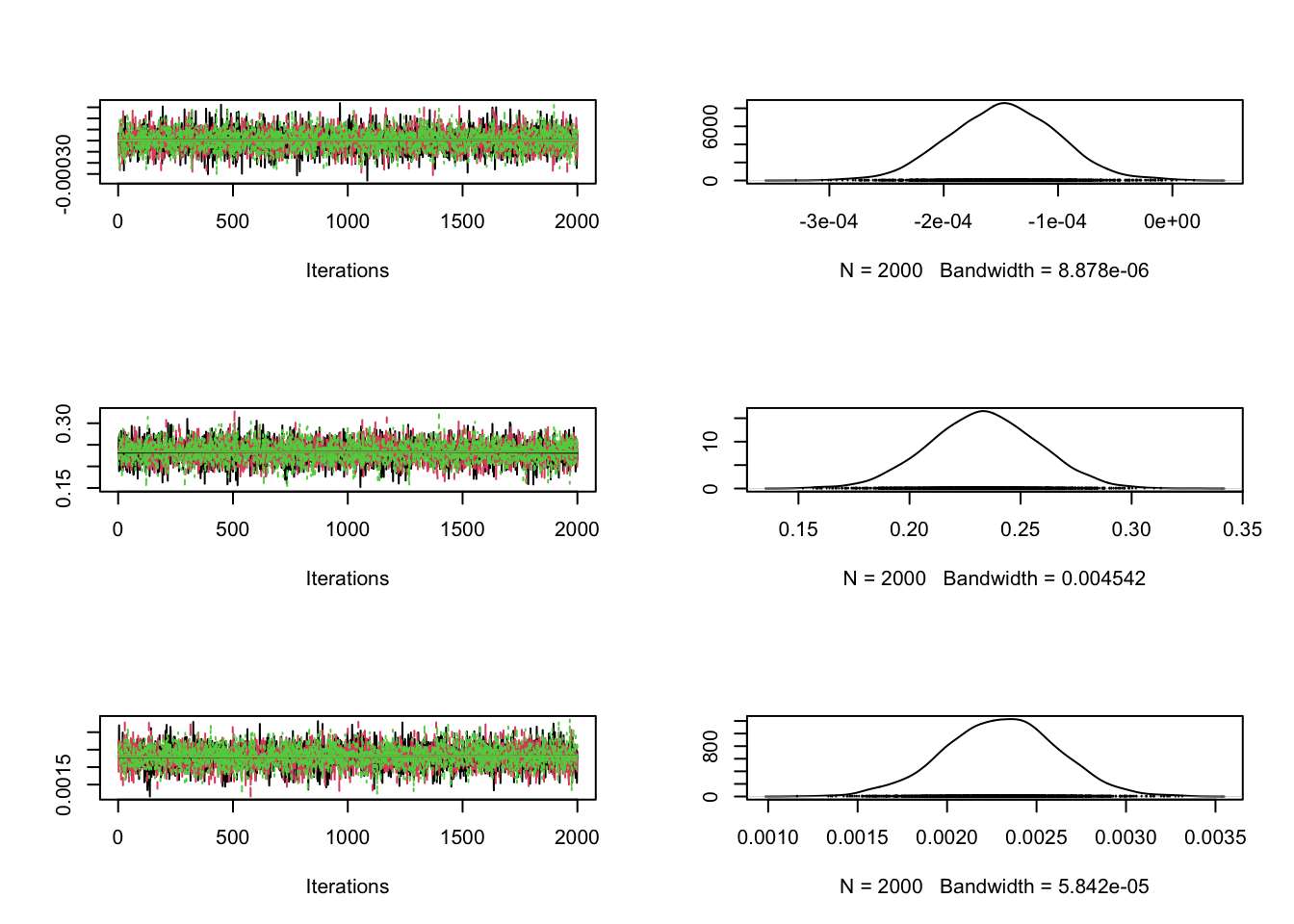
Now we are in a position to interpret the influence of the covariates.
##
## #################
## #### Model fitted
## #################
## Likelihood model - Gaussian (identity link function)
## Random effects model - Leroux CAR
## Regression equation - logprice ~ crime + rooms + sales + factor(type) + driveshop
##
##
## #################
## #### MCMC details
## #################
## Total number of post burnin and thinned MCMC samples generated - 6000
## Number of MCMC chains used - 3
## Length of the burnin period used for each chain - 1e+05
## Amount of thinning used - 100
##
## ############
## #### Results
## ############
## Posterior quantities and DIC
##
## Mean 2.5% 97.5% n.effective PSRF (upper 95% CI)
## (Intercept) 4.1368 3.8750 4.3951 6215.8 1
## crime -0.0001 -0.0002 -0.0001 6000.0 1
## rooms 0.2334 0.1860 0.2814 6251.4 1
## sales 0.0023 0.0017 0.0029 6000.0 1
## factor(type)flat -0.2947 -0.4034 -0.1882 6000.0 1
## factor(type)semi -0.1728 -0.2709 -0.0767 6000.0 1
## factor(type)terrace -0.3247 -0.4491 -0.2031 6426.3 1
## driveshop 0.0036 -0.0302 0.0380 6000.0 1
## nu2 0.0224 0.0118 0.0328 5677.7 1
## tau2 0.0537 0.0246 0.0962 5979.6 1
## rho 0.9094 0.7212 0.9904 5771.8 1
##
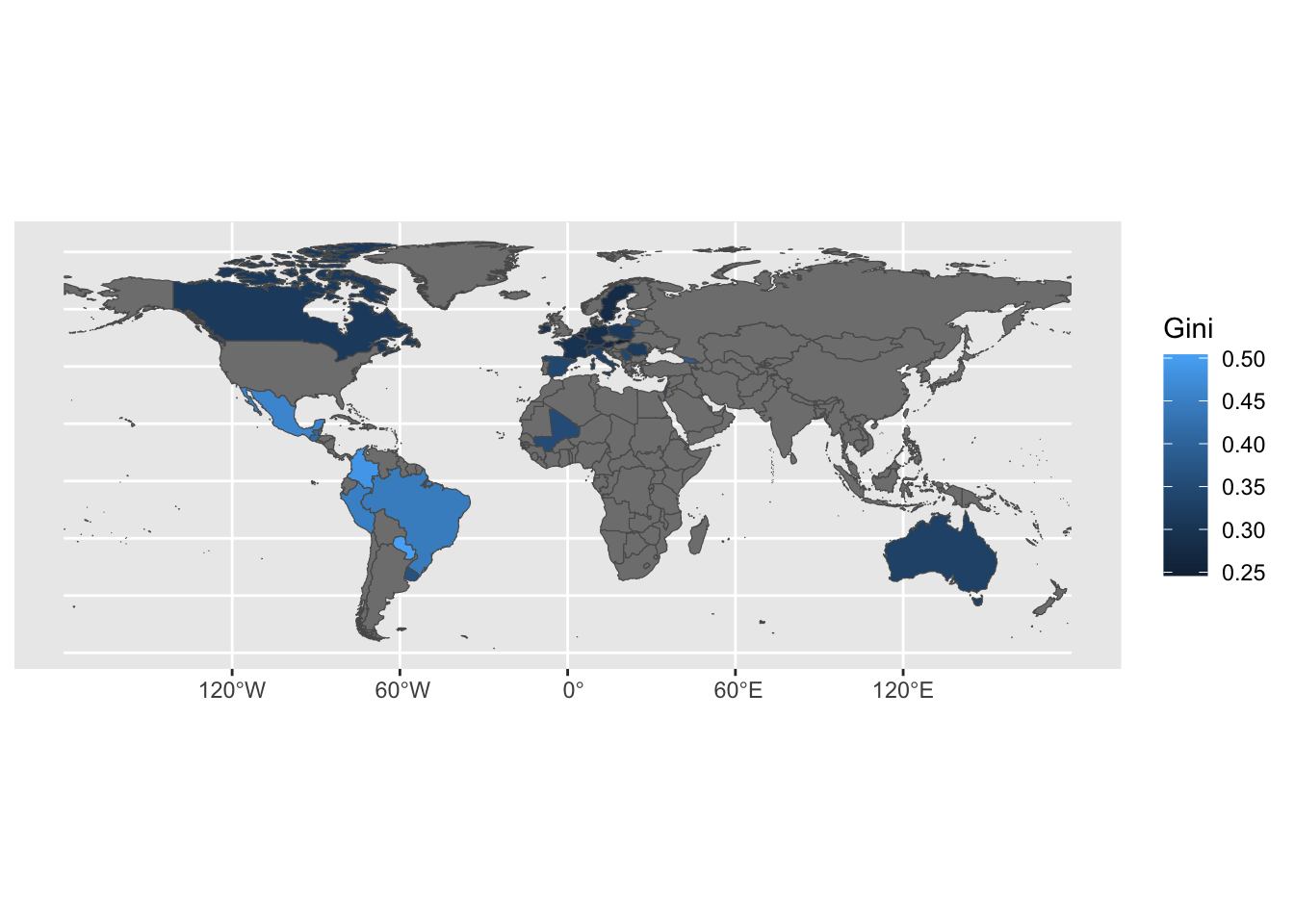
## DIC = -162.7665 p.d = 104.7579 LMPL = 60.36A further exanmple on poverty indicators.
Download Luxembourg inequality data from: https://ourworldindata.org/explorers/inequality-lis Download the .csv file.
Download world country boundaries from: https://public.opendatasoft.com/explore/dataset/world-administrative-boundaries/export/
The code below needs the path to the folder containing the downloaded inequality-lis.csv file to be assigned to path.csv and the path to the folder containing the downloaded folder world-administrative-boundaries to path.shp.
library(tidyverse)
library(sf)
path <- paste(path.shp, "inequality-lis.csv", sep = "/")
inequality <- read_csv(path) %>%
filter(Year == 2014) %>%
rename(Gini = 3)
path <- paste(path.shp, "world-administrative-boundaries/world-administrative-boundaries.shp",
sep = "/")
world <- read_sf(path)
world <- full_join(world, inequality, c("name" = "Country"))
ggplot(world, aes(fill = Gini)) + geom_sf()